Electronic discovery, commonly referred to as e-discovery (eDiscovery Process), encompasses the electronic processes involved in identifying, collecting, and producing electronically stored information (ESI) in response to requests during legal proceedings or investigations. ESI comprises a wide range of data types, including emails, documents, presentations, databases, voicemail, audio and video files, social media content, and websites.
Here is a definition I found, that might make it easier to understand eDiscovery as a business asset:
eDiscovery allows you to discover and manage your data in one place, enabling efficient response to legal matters or internal investigations with intelligent capabilities that filter data to only what’s relevant. — https://cwisecurity.com
The e-discovery process is often complex due to the vast amounts of electronic data generated and retained. Unlike physical evidence, electronic documents are essentially dynamic and frequently include metadata, such as timestamps, author and recipient details, and record attributes. It is essential to maintain the preservation of both the original content and its metadata (data about data, i.e. creation date, author, etc.) to prevent tainting or spoliation or evidence tampering during litigation.
![]()
Once the parties involved in a case identify relevant data, both electronic and physical documents are placed under a legal hold, which prohibits any modifications, deletions, or destruction. The relevant data is then collected, extracted, indexed, and organized into a database such as Relativity, or Brainspace. At this stage, the data undergoes analysis to filter out clearly irrelevant documents and emails.
Afterwards, the data is stored in a secure environment, where it becomes accessible to reviewers who assess/review the documents for their relevance to the case, often involving contract attorneys, paralegals, and experts in this review process.
Ediscovery Software
Relativity can take care of all the steps involved in the eDiscovery process, however a company may just decide to use it just as a database to host their documents for review. For instance, I worked for a company that used LexisNexis to process all the documents, however they only hosted on Relativity DB. There are multiple such tools you will come across during your eDiscovery journey. Although each tool has it’s advantages/disadvantages, overall they generally work the same.
For the purpose of creating a production, relevant documents are further sifted, using Computer Assisted Review (C.A.R.), or more commonly known as Technology Assisted Review (T.A.R.), predictive coding, and other analytical eDiscovery software. This significantly reduces the volume of documents that the attorneys, or paralegals must review, thereby enhancing the efficiency of the legal team.
EDRM
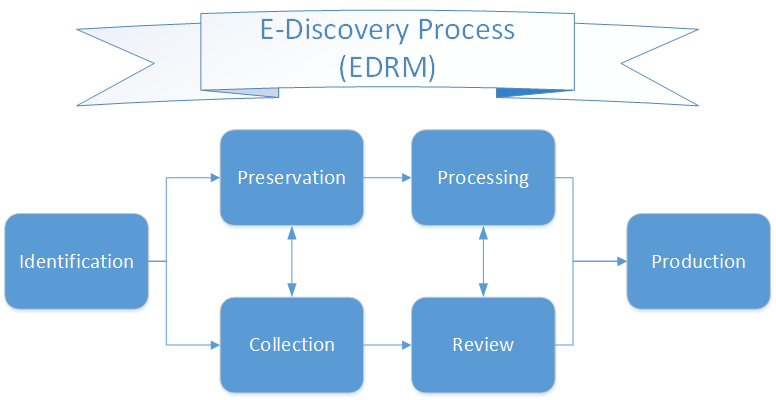
Above, I created a model of the electronic discovery process in Microsoft Visio, commonly referred to as the EDRM. EDRM is short for Electronic Discovery Reference Model and clarifies the steps involved in the process. Here is what each of the rectangles represent:
Identification refers to selecting a segment of the documents that may contain useful information. This could include physical papers that need to be scanned, emails, pdfs, office, and other types of documents.
Preservation means we need to preserve the data as is and keep it from being altered. This is so we can access the original metadata of the document. Metadata including, date created, date sent, document name, email title, etc. need to be the original value.
Collection refers to actually copying the data we identified during the Identification phase, while maintaining original format. These documents will need to be processed.
Processing means we will feed all the collected data into software, such as LAW or Relativity, so we can extract the metadata as well as image and OCR the documents. This will allow us to further narrow the document set by allowing us to search the documents data.
Reviewing stage allows us to further sift the data, allowing us to determine which documents are responsive, which documents need to be withheld due to privacy, and/or which documents need to be redacted. The final set of documents remaining after this phase, go onto the next phase.
Production is the final stage for the documents (ESI). These documents will be delivered to opposing parties and others. In this stage, the documents will get production numbers, redactions and any privilege endorsements as specified during the review phase. Finally, these documents will be exported and delivered in the format requested. A production generally includes Images, Text, Natives, and Loadfiles, which can be processed by the other party and loaded into their own database.
Summary
As you can see, the Ediscovery process is a fairly detailed process that defines how to collect and preserve data. The final remaining documents are published in a “production”. After one production is complete, the remaining documents can be reviewed further, or more documents can be collected and added to the database.
The Ediscovery process is an ongoing process and most of the time, multiple productions are created per case. The most important factor is that the document integrity is protected. If the documents are a hard copy, they are scanned and turned into a digital format (usually pdf). Using tools such as LAW, Brainspace, Relativity, etc. allow us to view the documents and metadata in a easy-to-view format.

1 Comment
singhm · April 12, 2025 at 8:47 pm
This is a test comment.